Name node & Data node

Name Node
Name node는 블럭의 위치, 권한 등의 메타 데이터를 가진다. 기본적으로 메모리에 메타데이터를 저장하고 2가지 종류의 파일로도 기록한다.
1. Fsimage : File System Image로 네임노드 생성 이후부터 namespace 정보를 모두 가지고 있다.
2. Edit log : Fsimage로부터 현재까지의 변경사항 로그이다.
이제는 Name node의 기능을 알아보자.
- Metadata Management
- 파일 시스템을 유지하기 위한 메타데이터를 관리한다. 파일 시스템 이미지(파일명, 디렉토리, 사이즈, 권한 정보)와 파일에 대한 블럭 매핑 정보를 가지고 있으며 빠르게 응답해야 하기 때문에 메모리에서 관리한다.
- File System Namespace의 모든 변경사항을 관리한다.
- Data Node Management
- Data node들을 관리, 유지, 변경한다.
- Data Node Monitoring
- Data node는 Name node에게 3초 마다 heart beat를 전송한다.
heart beat는 Data node 상태 정보와 Data node에 저장되어 있는 블럭 목록인 block report로 구성된다.
Name node는 heart beat 기반으로 Data node의 실행 상태, 용량 등을 관리한다. - 일정 기간 동안 heart beat를 보내지 않는 데이터 노드는 장애가 발생한 것으로 판단한다.
- Data node는 Name node에게 3초 마다 heart beat를 전송한다.
- Block Management
- 블럭에 대한 정보를 관리한다.
어디에 블럭을 복제할 지, 블럭 이동, 복제본을 관리한다.
- 블럭에 대한 정보를 관리한다.
- Client Request
- Client가 HDFS에 접근할 때 항상 name node 먼저 접속한다.
파일을 저장하는 경우, 기존 파일 유무, 권환 등을 확인한다. 조회할 때는 실제 블럭의 위치 정보를 제공한다.
- Client가 HDFS에 접근할 때 항상 name node 먼저 접속한다.
Data Node
Client가 HDFS에 저장하는 파일을 디스크에 유지한다.
크게 2종류의 파일이 있다.
1. 실제 데이터인 raw 데이터
2. checksum, created time 등 메타데이터가 설정된 파일
Data node는
client로부터 데이터의 read/write 요청을 받고 처리한다.
Name node로부터 명령을 받고 자신의 디스크에 있는 블럭을 생성, 복제, 삭제한다.
자신의 상태를 Name node에게 heart beat 보낸다.
자신이 가진 블럭들의 리스트와 상태를 Name node에게 알린다.
Replication
Fault tolerance(고장 감내성)을 위해 파일을 입력하면 여러 개의 block으로 복제되고 각 파일마다 block size와 replication factor가 지정된다.
어플리케이션은 파일의 replica 수를 지정할 수 있고 이것을 replication factor라고 한다.
replication factor는 파일 생성 시점에 정해지고 생성 이후에도 변경할 수 있다.
특히 HDFS 파일들은 한 순간에 하나의 writer만 존재한다.(append, truncate 제외)
Block의 replication에 대한 결정들은 Name node가 한다.
Replica Placement
Replica 위치는 reliability와 performance에 큰 영향을 미친다.
Rack-aware Replica Placement
대표적인 HDFS의 replica placement 정책 중 하나이다.
클러스터 내에 존재하는 여러 인스턴스들을 Rack 안에 위치시킨다.
서로 다른 렉끼리는 switch를 거쳐 통신하기에 같은 렉 안에서의 통신이 더 비용이 적다.
하둡 Rack Awareness 를 통해 name node는 각 data node의 rack id를 알고있다.
replica를 서로 다른 rack에 위치시켜 하나의 rack이 장애가 났을 때의 데이터 유실을 방지한다.
또한 이런 구조는 부하를 분산하는 효과도 가진다. 그래도 여러 rack에 걸쳐 write를 해야하기에 비용은 증가한다.
Block Placement Policy Default
대부분 replica factor는 3으로
하나의 replica는 가능한 writer와 같은 렉, 다른 노드에 위치하도록 한다. 그리고 다른 2개의 replica는 다른 렉의 서로 다른 data node에 저장된다. 그래서 unique rack의 개수는 2이다.
이렇게 하면 write할 때 렉 간에 발생하는 traffic을 줄이면서,
node failure 가능성 보다는 rack failure 가능성이 낮다는 가정하에 reliability와 availability가 좋아진다.
그렇지만 렉 사이에 데이터들이 골고루 분산되지 못하며, 총 network bandwidth를 줄이지 못한다.
아래 상한선 계산으로 replica factor가 4 이상이면, 하나의 렉 안에 replica 개수를 상한선 아래로 유지한다.
상한선 = (replicas-1) / racks+2
Safemode
name node가 처음 가동될 때 safemode에 들어간다.
sademode에서 replication이 발생하지 않는다.
복제를 수행하려면 기존 모든 블럭에 대한 replication이 일정 수준(%) 넘어 잘 구성됐다면, 그 때 safemode에서 나와 복제를 수행한다.
File Read/Write
Read Process
- Client가 File system으로 open 요청을 보낸다.
- RPC로 Namenode에 연결하고 읽으려는 파일의 메타데이터를 조회한다.
- 해당 파일이 저장되어 있는 블록 주소를 전달한다.
- 받은 Datanode 주소 정보로 FSDataInputStream 객체를 만들어 client에게 전달된다. 그리고 FSDataInputStream는 DataNode 와 NameNode 와 상호작용할 수 있는 DFSInputStream을 가지고 있다. client가 DFSInputStream에 대해 read를 요청하고 해당 파일의 첫 번째 블럭이 있는 datanode와 connection을 맺는다.
- 이때 Local Block First - 자신과 가까운 로컬 데이터 노드에서 먼저 데이터를 읽는다.
Rack Awareness - 자신과 같은 rack에 위치한 데이터를 읽는다.
에 따라 동작한다.
read() method 호출 할 때마다 stream 형태로 반환한다. End of block에 도달할 때까지 지속된다. - DFSInputStream은 Data node와 연결을 끊고 다음 Block이 위치한 Data node와 연결한다. 이 과정을 반복한다.
- read가 끝나면 client가 close()로 모든 연결과 Stream을 닫고 끝낸다.
Write Process
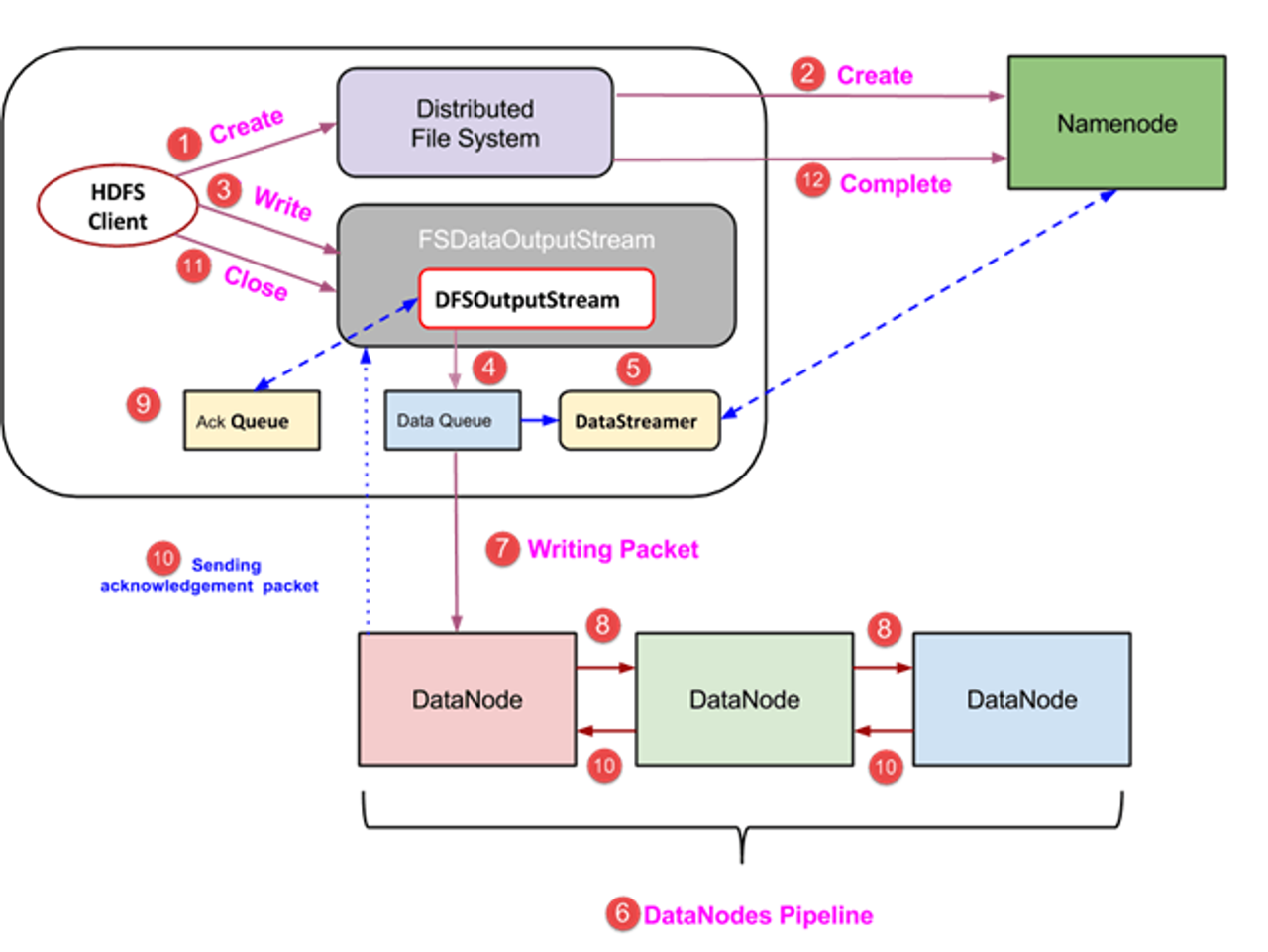
- Client가 Distributed File System object에 create 함수로 요청한다.
- RPC로 Namenode에 연결을 맺는다. 그리고 Namenode가 새로운 파일 생성 요청에 대한 verification(이미 존재 하는지, 경로에 대한 권한 등 확인)을 한다.
- namenode에서 파일 record가 생성되면 FSDataOutputStream으로 write를 시작한다.
- FSDataOutputStream은 datanode, namenode와 상호작용 하는 DFSOutputStream을 가지고 있다. DFSOutputStream은 client가 데이터를 쓰기위한 패킷을 만든다. 그리고 이 패킷은 Data Queue에 들어간다.
- DataSteamer는 Namenode에 적당한 datanode내 새 block 할당을 요청한다.
- Replication은 Datanode 들로 Pipeline을 만들면서 시작한다. replica factor를 3으로 생성하면 위의 그림처럼 3개의 Datanode로 구성되는 pipeline이 생성된다.
- DataStreamer는 DataQueue로부터 데이터를 가져와 파이프라인 첫 번째 Datanode에 저장할 패킷을 전송한다.
- Datanode는 받은 패킷을 모두 저장하고 다음 Datanode로 forward한다.
- Ack Queue는 각 Datanode가 성공적으로 write를 마치면 신호를 보내는 곳이다.
- 모든 Datanode로 부터 성공했다는 ack가 다 들어오면 queue를 삭제하고 만약 아니라면 ack 전송을 안한 Datanode에 다시 write를 요청할 수 있다.
- write를 마치면 client가 close 함수를 호출하고 남은 data 패킷을 flush하고 ack를 기다린다.
- 마지막 ack가 도착하면 client는 namenode에 write가 끝났음을 알려준다.
'Data Engineering > Hadoop' 카테고리의 다른 글
| Hadoop RAID, Eraser Coding (1) | 2024.01.08 |
|---|---|
| Observer Name Node(ONN)로 부하 분산 (0) | 2024.01.08 |
| Hadoop의 High Availability (고가용성) 아키텍처 (1) | 2024.01.08 |
| HDFS Design Goal & Block Based File System (0) | 2024.01.07 |
| Hadoop 소개 (1) | 2024.01.07 |